AIの概要 をざっくりと説明します
AI では 記述言語がそもそも数学 で、
・線形代数
・微分積分
・確率・統計
の知識を使いますが、かなり専門的になるので、概念的な説明までとなります。
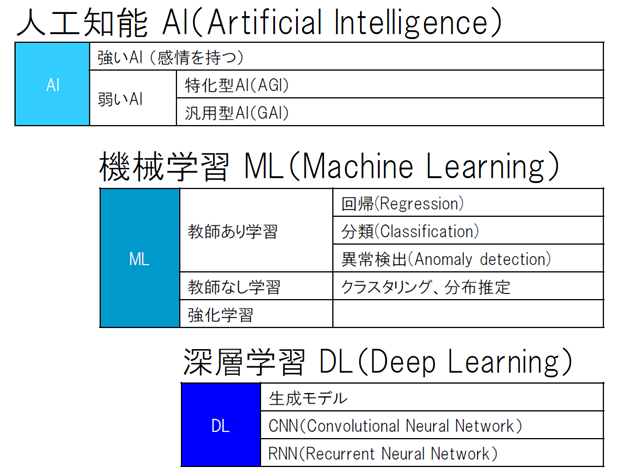
AIの分類 – 種類
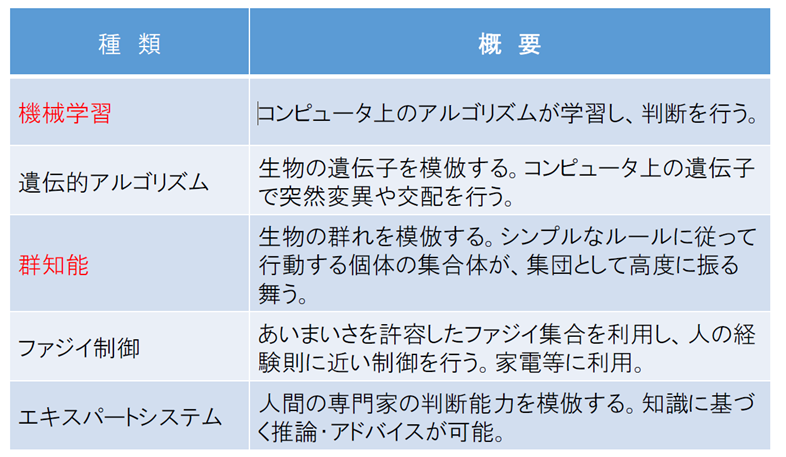
郡知能(Swarm Intelligences)

AI 外観(ハードウェア)



Python for AI Development

- シンプルで読みやすい 文法
- 強力な内省イントロスペクション 機能 •直感的なオブジェクト指向
- 手続き型のコードによる、自然な表現
- パッケージの階層化もサポートした、完全なモジュール化サポート
- 例外ベースのエラーハンドリング
- 高レベルな動的データ型
- 広範囲に及ぶ標準ライブラリとサードパーティのモジュール •拡張とモジュールはC/C++ で書くのが 容易( Java 、 .NET も利用可 •アプリケーションに組み込んでスクリプトインタフェースとして使える
クラウド処理とエッジ処理 – 1
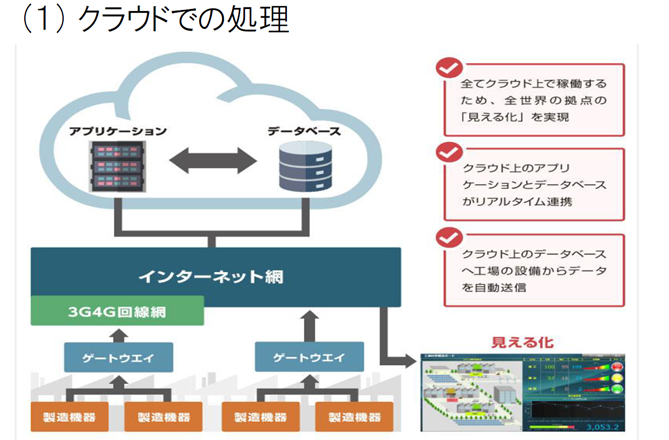
クラウド処理とエッジ処理 – 2
データ処理増大に伴い、すべてをクラウド側で処理するのに不都合が出てきた。これからはエッジコンピューティング が使われる
- 通信料やクラウド利用料が増大する
- インターネット経由で処理速度が遅くなる
- セキュリティー的にデータをクラウドに上げたくない
- ネット環境が不安定だと処理が止まる
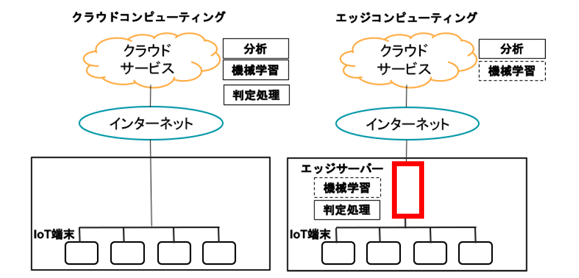
パターン1:機械学習はクラウドで行い、学習済みモデルをエッジで処理する。
パターン2:機械学習もエッジで行い、クラウドは分析に利用する。
機械学習(Machine Learning)
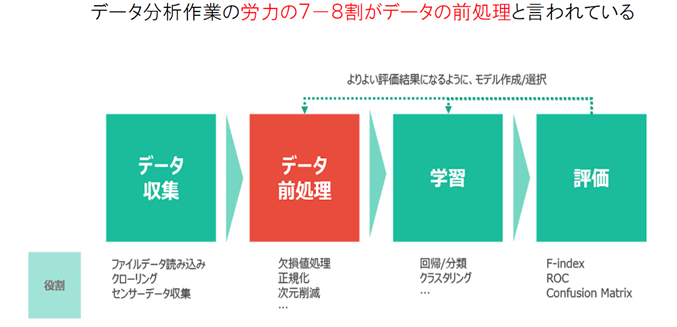
機械学習: データから反復的に学習し、そこに潜むパターンを 見つけ出し、学習結果 を新たなデータ に適用し予測 する こと
統計との違い
機械学習:大量のデータを分析 し、今後を 予測するの が目的
統計:データがどのようなものであるの か 説明するの が目的

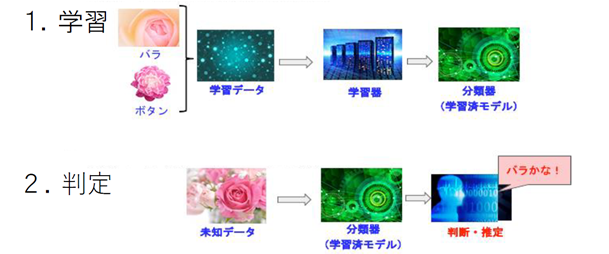
「学習」と「判定・推論」の2フェーズ
1.学習:訓練 データ で学習モデルを作成する
2.判定:学習済みのモデルを使って未知のデータを推定する
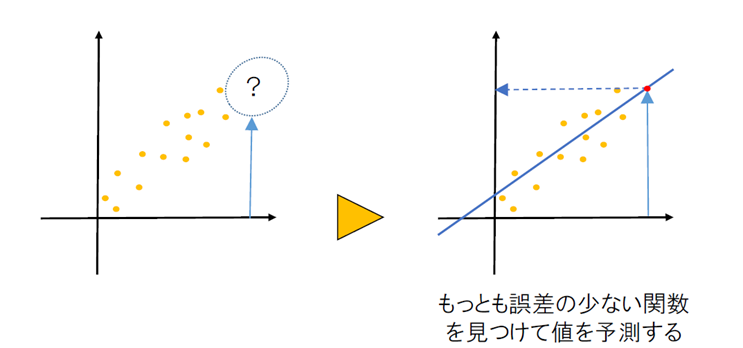
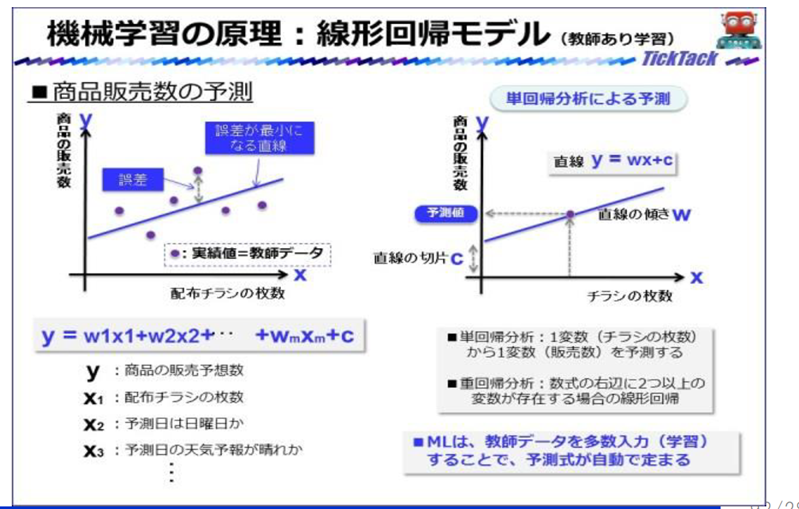
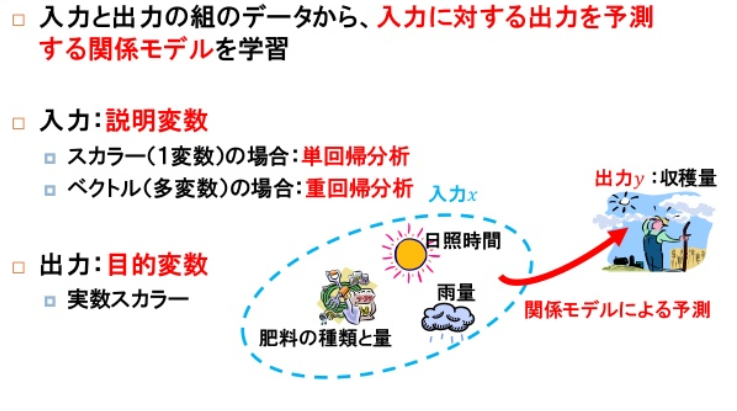
機械学習(回帰regression)
入力値に対する出力 値を予測 し、その結果を求める場合に使う
例:集客人数や商品の売り上げ予測など
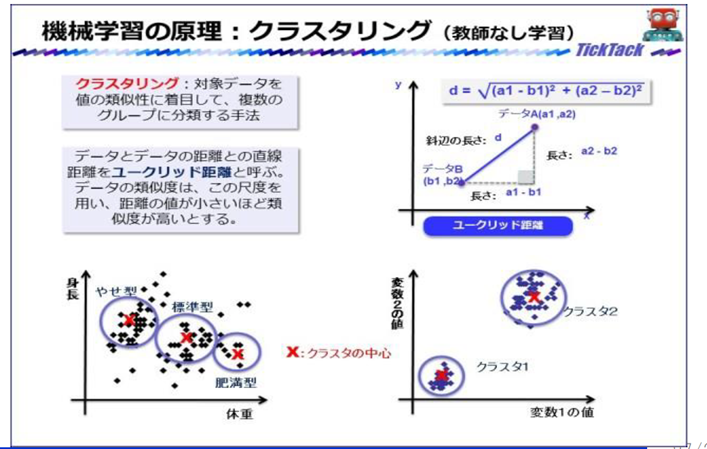
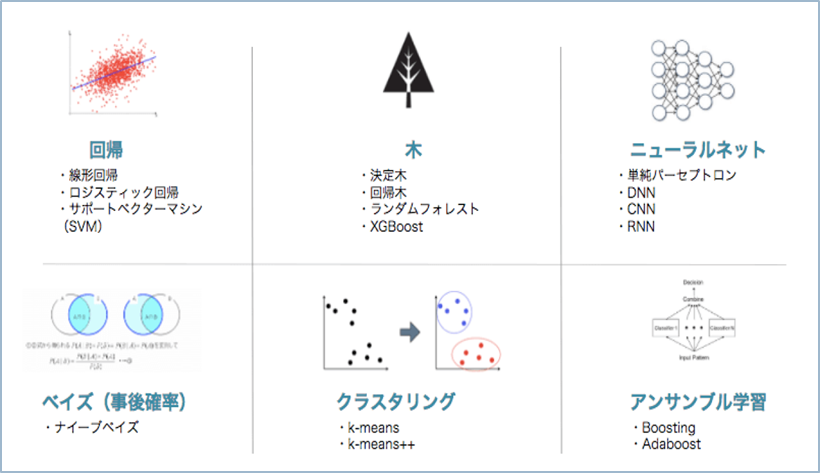
機械学習(いろいろな手法がある)
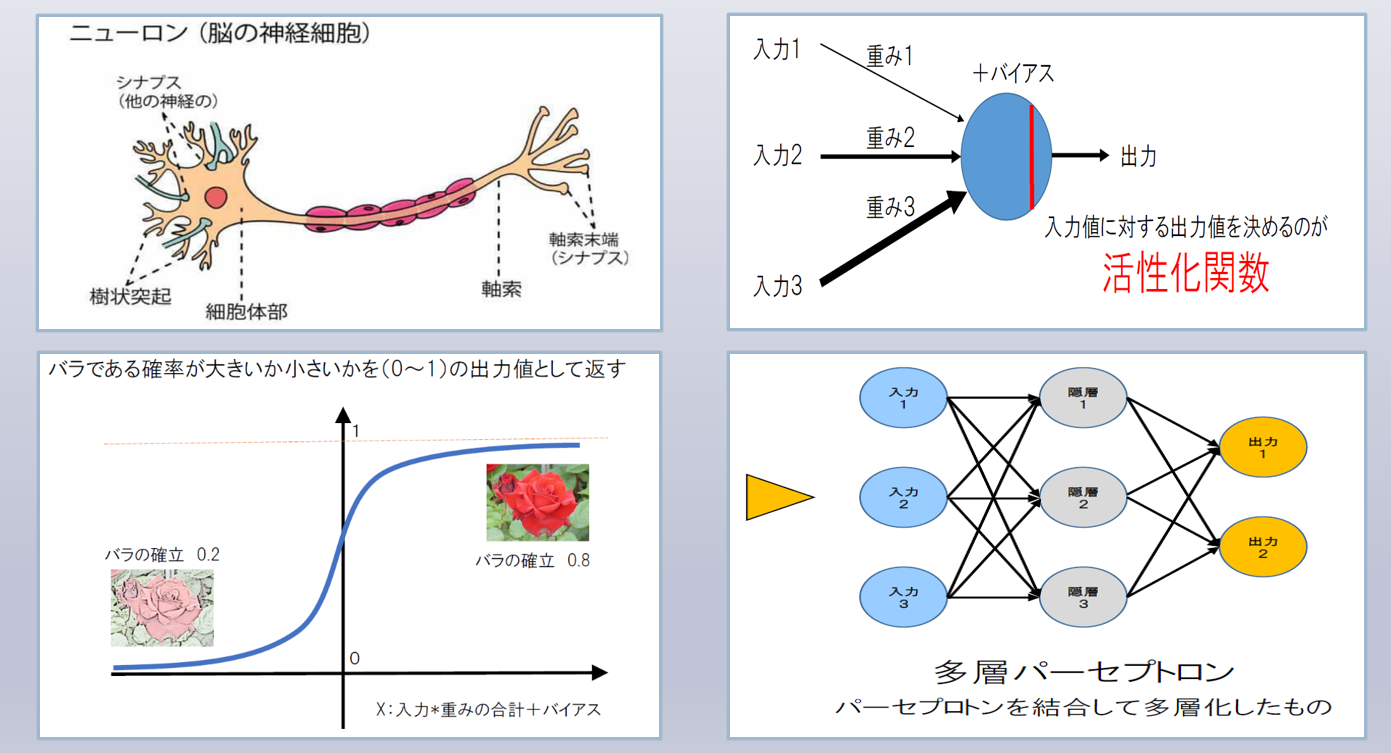
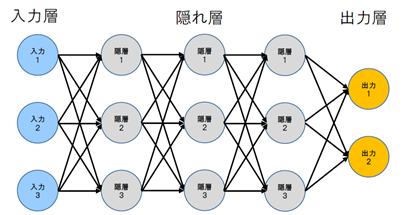
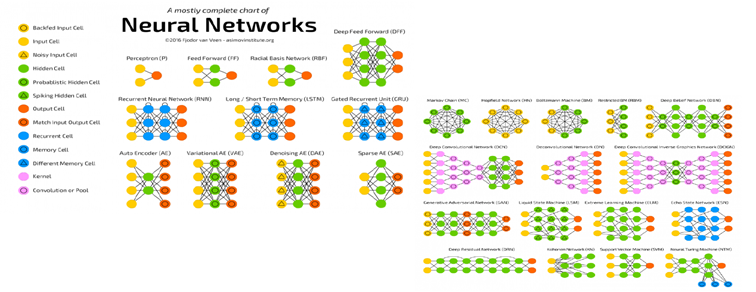
ニューラルネットワーク
◇パーセプトロン : 人間の脳を模した数学モデル
深層学習(Deep Learning)
ニューラルネットワークを深く多層化したものを使って学習することをディープラーニングと言う。
(何層以上という明確な規定はない)
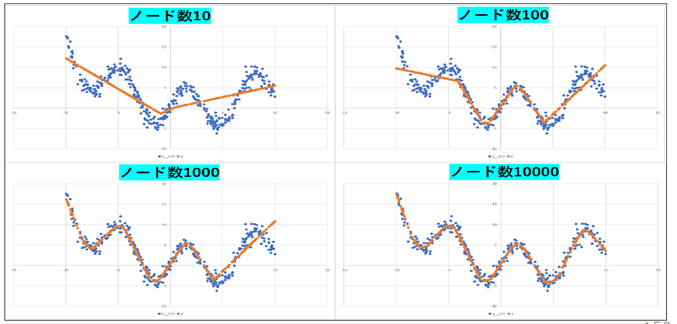
層 を増やすと何がいいのか
線形関数だけでなく、複雑な非線形関数も近似できるようになる → 適合度が高くなる
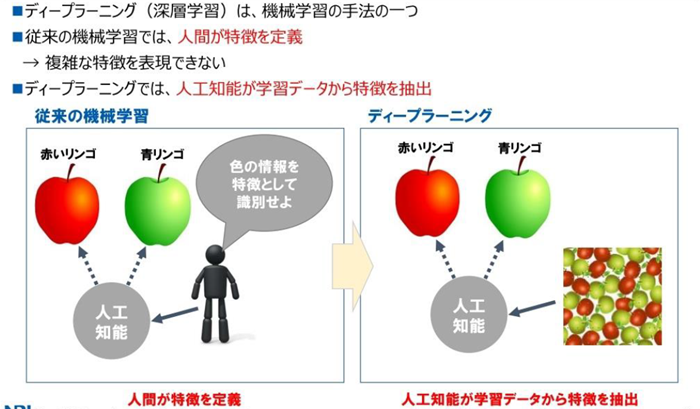
機械学習と深層学習の 違い
- 機械学習:特徴量を人が見つけて指定する
- 深層学習:大量のデータから AI が自分で見つける
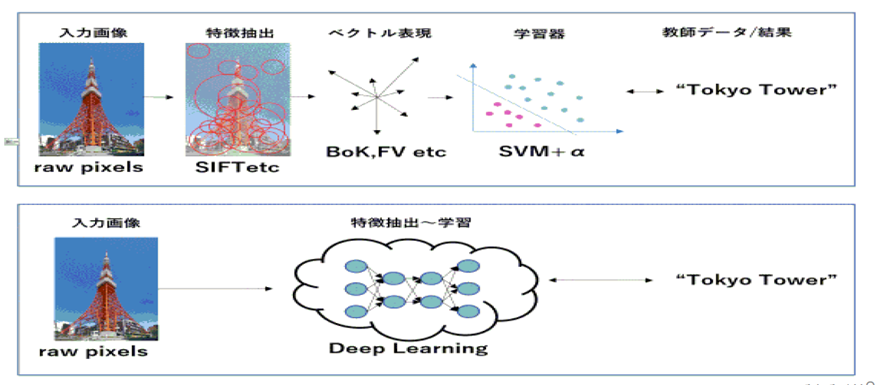
Deeplearningは特徴抽出などを自動で行う
注目されるきっかけ
ILSVRC
- 画像認識の国際競技会 )での圧勝
- 2012年 の大会で、トロント大学の Hinton 教授の チームが Deep Learning を使って圧勝した。
- Deep Learning は 2015 年の大会から人間の認識能力を超えた。
- ヒントン教授が立ち上げたベンチャーはGoogle が買収した。
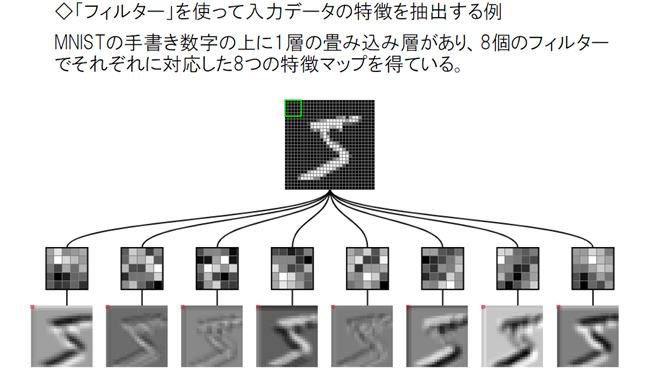
CNN畳み込み ネットワーク Convolutional Neural Network

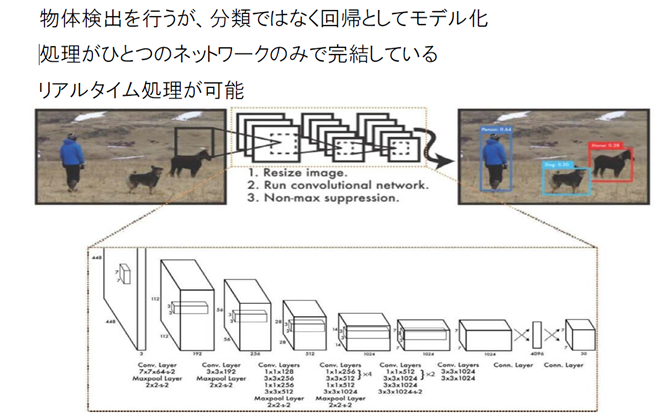
CNN YOLO (You Look Only Once)
RNN 再帰型ニューラルネットワーク

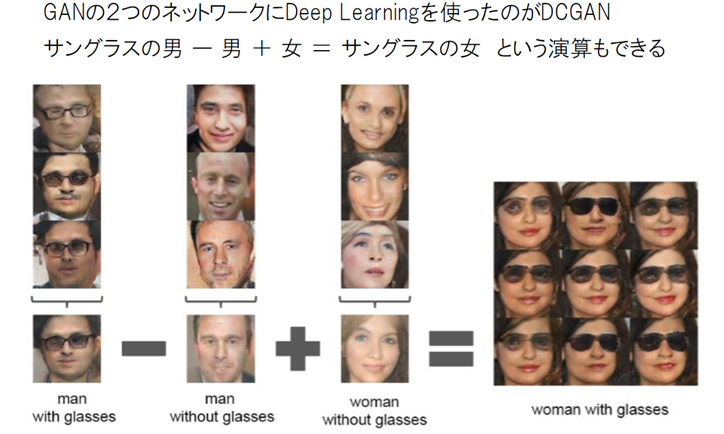
生成モデル: GAN DCGAN
ディープラーニング 深層学習 の問題点
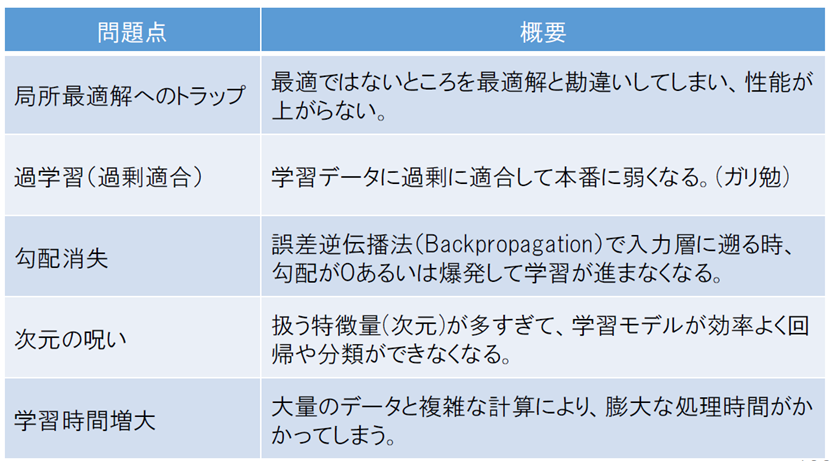
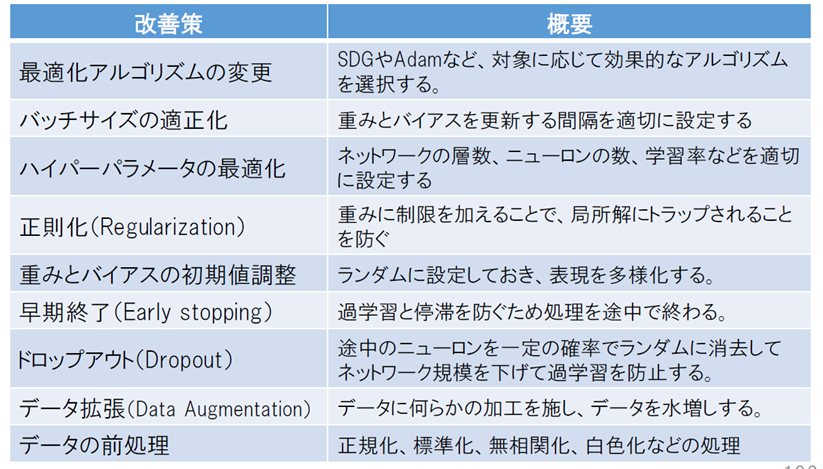
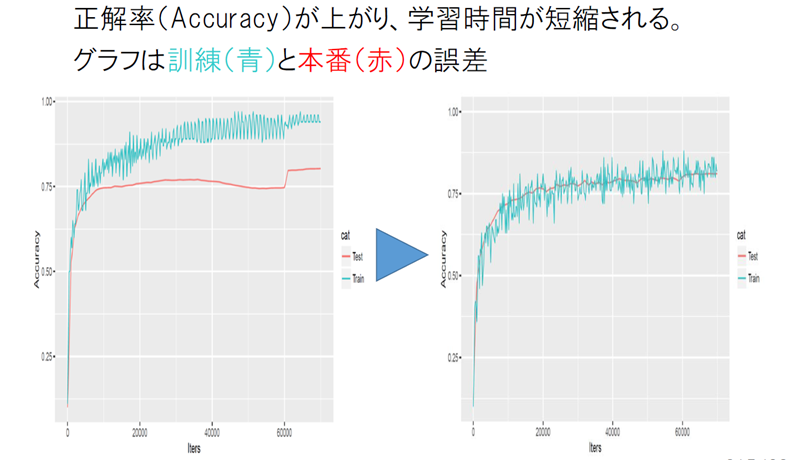
ディープラーニング問題解決へのアプローチ
深層強化学習: AI
ゲームのルールをまったく知らなくても、自己学習を繰り返し 、どんどん強くなって最後は人間にも完勝するような AI を作れる。
↓
DQN Deep Q Network )がゲームを自己学習する様子 2015 年)
強化学習の方策(状態から行動を返す関数)や価値関数(状態・行動に対する収益の期待値)をディープラーニングを用いて求める手法を「深層強化学習」と言う
- 動的計画法
- モンテカルロ法
- TD(temporal difference; 時間的差分 学習)
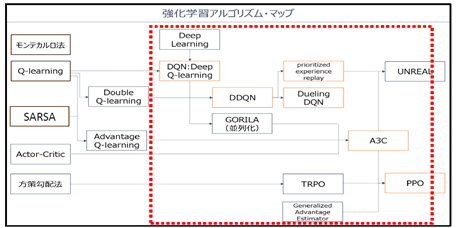
深層強化学習: 各種アルゴリズムの開発
DQN をきっかけに、様々なアルゴリズムが次々に提案され、劇的な性能向上が続いている
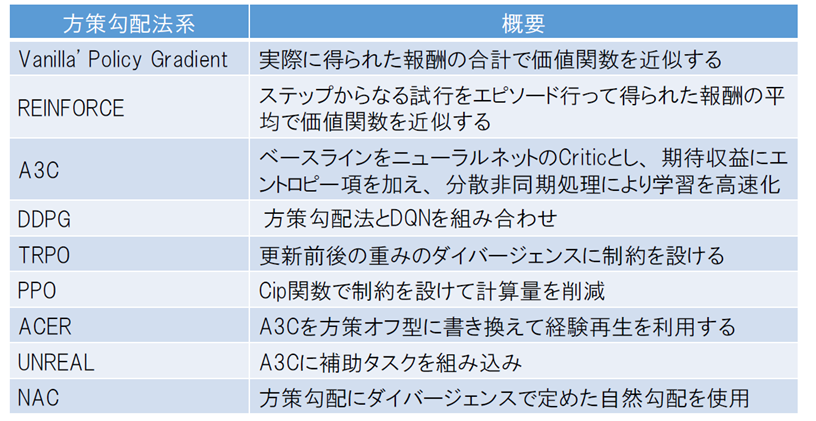
深層強化学習: 各種アルゴリズムの開発
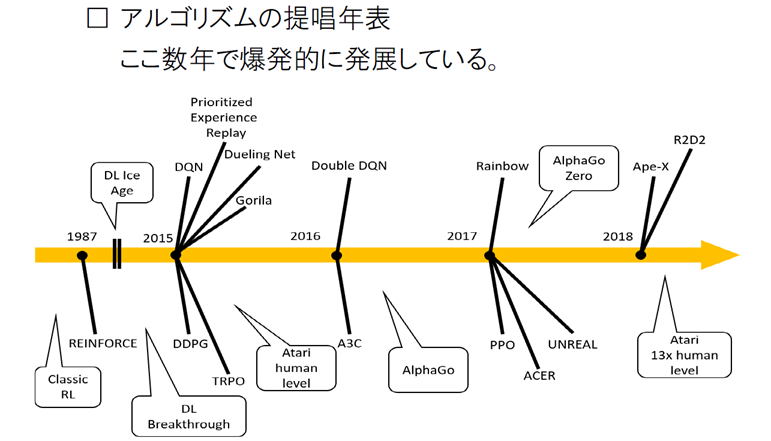
深層強化学習: 応用例 ゲーム

深層強化学習: 応用例 ロボット

深層強化学習: 人間を超える能力
複数のモデルを組み合わせ、自己学習を繰り返し、人間を超 える
AlphaGoの例:
碁の盤面から打つ手の有効性を判断 するのに CNN を用い、パラメータ を対戦相手への勝利を報酬のフィードバックとして使って強化学習で訓練して いく。 その後、モンテカルロ木探索で有望な手をさらに深く 探索する。

急拡大するAIが生活を変えている
◇金融大手ゴールドマンサックス
AI リストラで500人のトレーダーが3人に激減
エンジニアは9000人を雇用
◇配車サービスのUber台頭
アメリカ最大手のタクシー会社YellowCabが倒産
運転手はNYだけで8万人。市当局が参入規制も。
◇AIに奪われる仕事オックスフォード大学マイケル・A・オズボーン准教授
アメリカでは、今後~20年の間に総雇用者の
半分の仕事が自動化されるリスクが高い
AIプラットフォーム

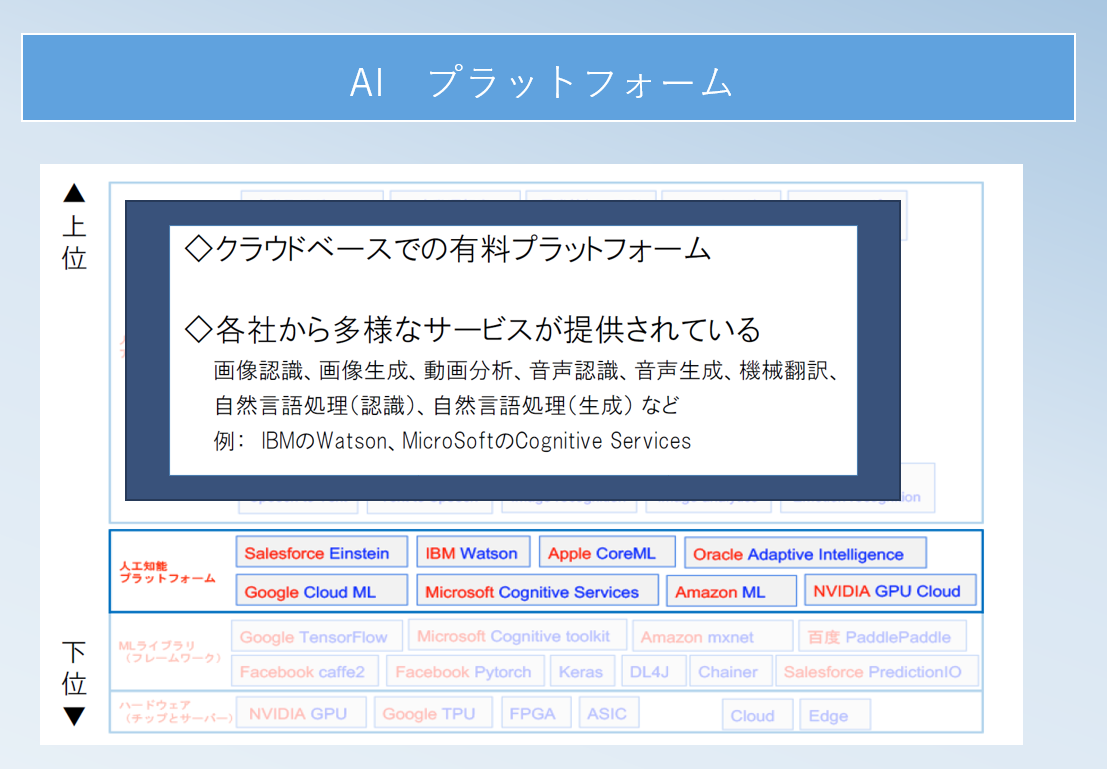
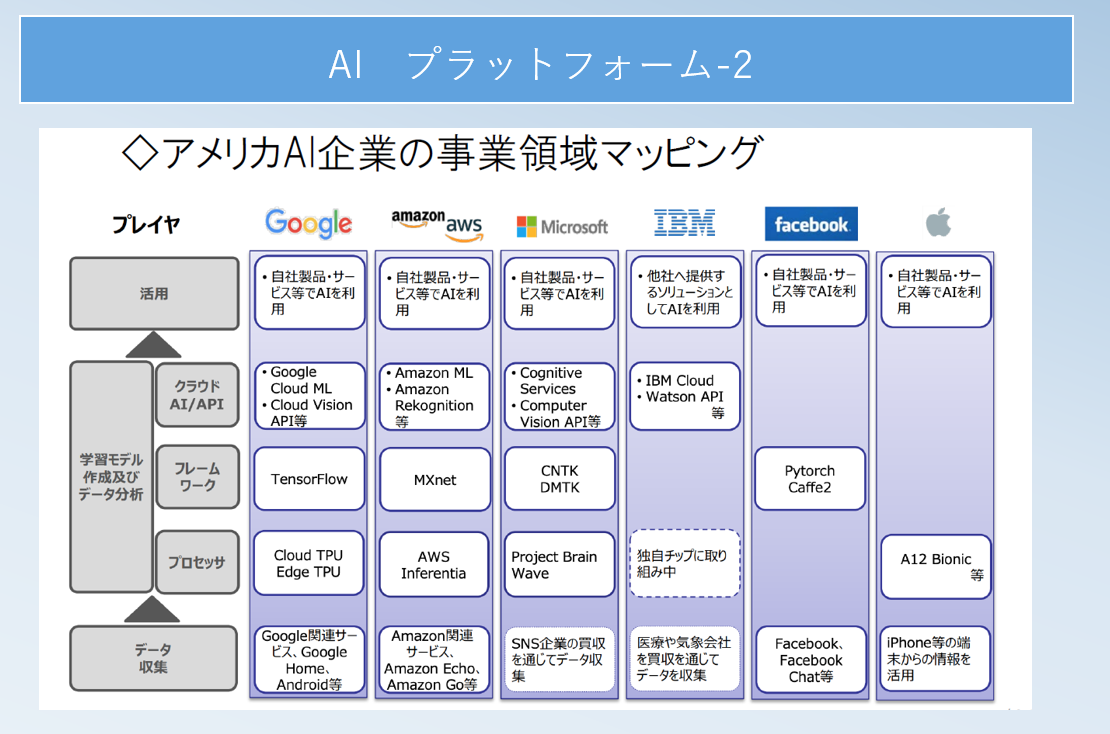
評価の仕方l
基本用語
- モデリング (仮設の数理的表現)→未知のデータを予測
- 最適な分布をどう作るか
- モデリングの最適化
- 単回帰
- ロジスティック回帰
- ニューラルネットワーク
- 最小二乗法 }
- 勾配降下法
回帰分析
評価指標
- 評価プロトコル }ホールドアウト法
- クロスバリエーション
- 単回帰 y=ax+b パラメータは一つ 単純な予測モデル
- E(Error)真の値との誤差
- 最小二乗法
多項式回帰
- Y=ax2+bx+c
- Y=ax3+bx2+cx+d
- 表現力が高い
- 誤差=損失(Loss)とも言われる
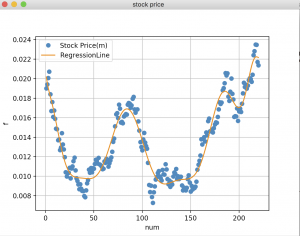
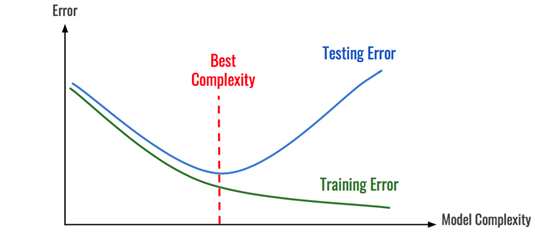
- Overfitting
- Underfitting
複雑さ、次元数が多ければよいというわけではない
汎化性能(Generalization Performance)
汎化性能を測る
評価プロトコル
- ホールドアウト法
- クロスバリエーション法
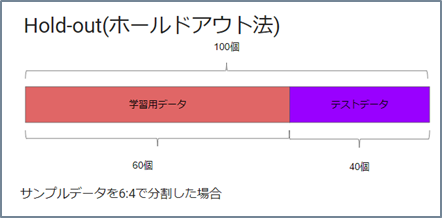

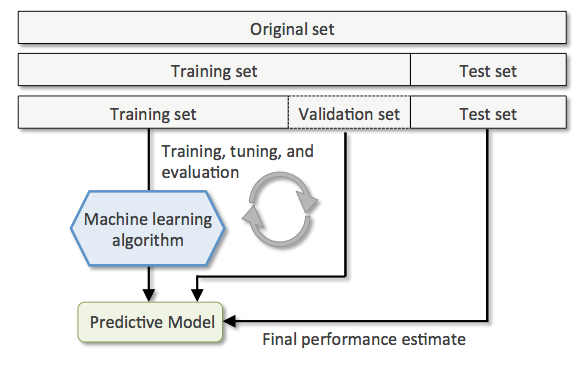
評価の仕方
訓練データ
- 検証データ
- テストデータ